���������ķ���һ�� Access ���� ��Ȼ Accessoft.com ��û���˱��ϵģ�
���ֻ��Ҫִ�� a= Instr( chr(-23124), "x")���ͻ����
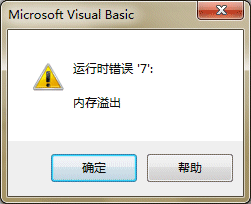
���DZ�Ȼ�Ĵ���
�ٶ�������鿴��ԭ�� Access VBA �������������
����˵����һ���ַ������������26���ձ�������һ���ͻ������
��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��
����� Bakka �ˣ�
Ϊʲô���ձ��־Ͳ��� Instr, like, replace �ˣ� ���������� �ַ������� ��������
�����Ҳ鿴�ҵ��ַ������������û����26����Ŷ��ֻ�Ǻܶ�Ļ����ģ��鷳�ˣ������ĸ��ַ��� VBA �����أ�
�����д��һ������ȥ���ʲô�ֻᱨ����
Public Sub ccccc()
Set rs = CurrentDb().OpenRecordset("cCode")
On Error Resume Next
For X = &H8140 To &HFEFE
tt = Chr(X)
Err.Clear
n = InStr(tt, "A")
If Err > 0 Then
rs.AddNew: rs!ccode = X:: rs.Update
End If
Next
End Sub
������е�˫�ֽ��ַ����� &H8140 - &HFEFE���������� ���պ�������������ַ���
��������ԭ����27����
��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|�d
���˸� 3Ʋ�� ����֪��ʲô�֣� ����� �����˲�֪���ˣ�
����˵�Ľ���������� �������� ȡ������ ���� ��Access VBA Instr �ڴ������ ����������һģһ���Ľ��������
���ǣ��Ҿ�����ˣ����Ƕ����� replace ��ȡ����ģ��ող���˵ instr, replace, like ��������
�������ҾͲ��ô�����Щ���ֵģ��Ҿ�û���� �����롱 �ķ������滻���Ҿ�����Ҫ�������Ե��Ϳ����ˣ�
�ҼIJ��Թ� StrConv Ҳû�취����������Ҿ����˷�VBA������ȥ�����ˣ������� �������ʽ��
Set re = New RegExp
re.Multiline = True
re.IgnoreCase = True
re.Global = True
re.pattern = "(?:��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|��|�d)"
tmpData = re.Replace(responseData, "")
responseData = tmpData
��� New RegExp ��Ҫ���ã� Microsoft RegExp 5.5 �Ŀ⣡
��������� ����ֵģ�ֱ���� responseData = re.Replace(responseData, "") �Dz��ܱ��滻���ģ������ˣ�������ʱ�����£�
�ҵĻ����� Win7 64λ + Office 2007����Ҳ�ͬ��ϵͳ�汾����ͬOffice�汾 ���ܻ��в�ͬ�ɣ��ҾͲ�֪���ˣ������£��ô���ٵ㷳�գ�
PS��������� Access VBA �����⣬�Ҳ��Թ� Excel 2007 ��û���������ģ�

