不好意思,今天才看到你的留言!
再来看看的意思是什么?看你那些 红蓝绿 的 涂鸦?真的是不想看的! 因为没有你的原始数据,要我录入一次来示范,好麻烦!
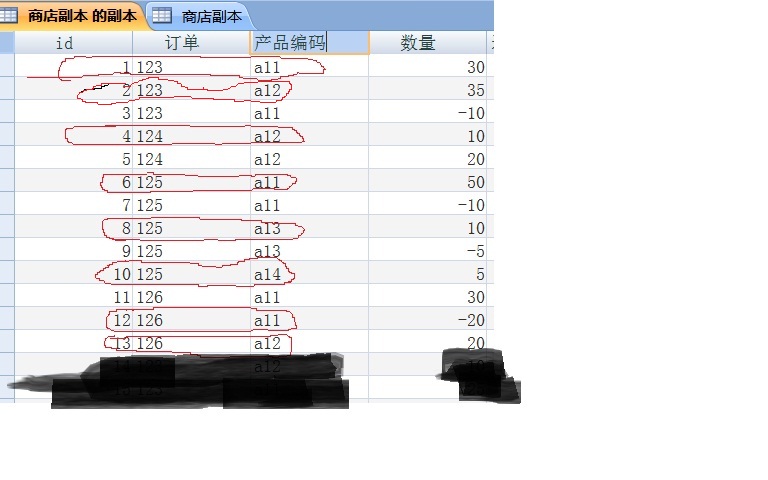
其实,你是数据库设计的失败,导致,不能一对多,因为这是多对多关系,而恰恰你又没有建这些表,所以难倒自己,难倒大家了!
我不想细看你的失误作品,所以我还是看看你的问题:
怎样只删除表中重复数据中的一条,如果数据没有重复的,那么就也删掉。
我给你的方法 有四个,既然你不介意重复的删掉 哪几条,反正留下一条就可以了,你就选第一个答案吧:
delete from 数据表
where id not in (
select min(id) from 数据表 group by 订单, 产品标号 having count(id)>1
)
这里,没有重复的,就删掉了;
有重复的 只保留重复的第一条。
应该对你的问题挺吻合的!
----------------------------------------------------
另外,我想说的是
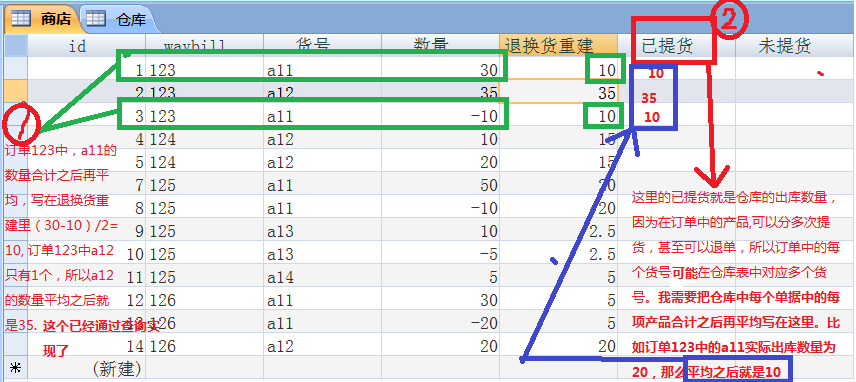
平均那个数好像没什么用,你只需要处理总数就可以了吧?
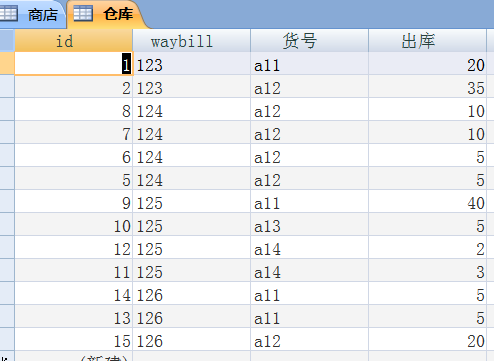
仓库的出货 与 商店 的 库存,我都说了是多对多的关系,
意思是,输入一张 仓库出库单,然后选 多个 商店waybill 并且填个 结算数量,
保存前 检查 waybill 所有的 结算数量 的 Sum 不能超过 waybill 商品 的 sum 为合格;
另外, 单个出库单-商品 的 结算数量的 Sum 不能超过 出库单-商品 的 Sum 为合格;
当这两个合格 就能保存。
可能事后 waybill-商品 发生变化,导致 这个结算 不均衡,就用个查询查个偏差出来就行了!