
SQL SERVER2005��������
ʱ����:2012-06-21 09:59:48
������:���ı� ID��4506 ���У�����
ժ��Ҫ:�п����õ�
������:
1. row_number
2. rank
3. dense_rank
4. ntile
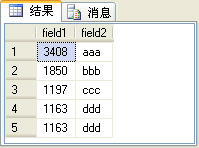
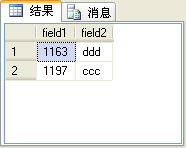
����ֱ����һ�����ĸ����������Ĺ��ܼ��÷����ڽ���֮ǰ������һ��t_table�������ṹ����е�������ͼ1��ʾ��
ͼ1
����field1�ֶε�������int��field2�ֶε�������varchar
һ��row_number
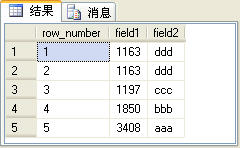
row_number��������;�Ƿdz��㷺����������Ĺ�����Ϊ��ѯ������ÿһ�м�¼����һ����š�row_number�������÷��������SQL�����ʾ��
�����SQL���IJ�ѯ�����ͼ2��ʾ��
ͼ2
����row_number������row_number�������ɵ�����С���ʹ��row_number������Ҫʹ��over�Ӿ�ѡ���ijһ�н�������Ȼ�����������š�
ʵ���ϣ�row_number����������ŵĻ���ԭ������ʹ��over�Ӿ��е��������Լ�¼��������Ȼ�������˳��������š�over�Ӿ��е�order by�Ӿ���SQL����е�order by�Ӿ�û���κι�ϵ����������order by ������ȫ��ͬ���������SQL�����ʾ��
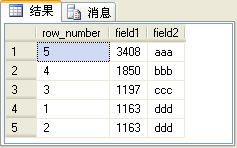
�����SQL���IJ�ѯ�����ͼ3��ʾ��
ͼ3
as
(
select row_number() over(order by field1) as row_number,* from t_table
)
select * from t_rowtable where row_number>1 and row_number < 4 order by field1
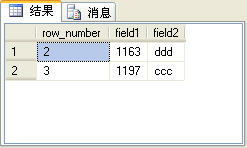
�����SQL���IJ�ѯ�����ͼ4��ʾ��
ͼ4
����Ҫע����ǣ������row_number�������ڷ�ҳ������over�Ӿ��е�order by �������¼��order by Ӧ��ͬ���������ɵ���ſ��ܲ��������ġ�
��Ȼ����ʹ��row_number����Ҳ����ʵ�ֲ�ѯָ����Χ�ļ�¼�����DZȽ��鷳��һ��ķ�����ʹ�õߵ�Top��ʵ�֣����磬��ѯt_table���е�2���͵�3����¼�������Ȳ��ǰ3����¼��Ȼ��ѯ��������������¼������������ȡǰ2����¼������ٽ����������2����¼�ٰ��������������ս����SQL������£�
�����SQL����ѯ�����Ľ����ͼ5��ʾ��
�����ѯ�������û�������row_number����������ͼ4��ʾ�IJ�ѯ�����ȫһ����
����rank
rank�������ǵ���over�Ӿ��������ֶ�ֵ��ͬ�������Ϊ�˸�����˵�����⣬��t_table�����ټ�һ����¼����ͼ6��ʾ��
��ͼ6��ʾ�ļ�¼�к�������¼��field1�ֶ�ֵ����ͬ�ġ����ʹ��rank������������ţ���3����¼���������ͬ�ģ�����4����¼����ݵ�ǰ�ļ�¼ ��������ţ�����ļ�¼�������ƣ�Ҳ����˵������������У���4����¼�������4��������2��rank������ʹ�÷�����row_number������ȫ�� ͬ��SQL������£�
�����SQL���IJ�ѯ�����ͼ7��ʾ��
����dense_rank
dense_rank�����Ĺ�����rank�������ƣ�ֻ�����������ʱ�������ģ���rank�������ɵ�����п��ܲ�����������������������ʹ��dense_rank��������4����¼�����Ӧ����2��������4���������SQL�����ʾ��
�����SQL���IJ�ѯ�����ͼ8��ʾ��
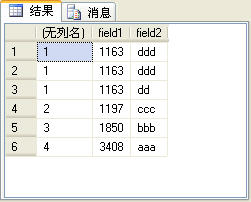
ͼ8
���߿��ԱȽ�ͼ7��ͼ8��ʾ�IJ�ѯ�����ʲô��ͬ
�ġ�ntilentile�������Զ���Ž��з��鴦��������൱�ڽ���ѯ�����ļ�¼���ŵ�ָ�����ȵ������У�ÿһ������Ԫ�ش��һ�������ļ�¼��ntile����Ϊÿ���� ¼���ɵ���ž���������¼���е�����Ԫ�ص���������1��ʼ����Ҳ���Խ�ÿһ�������¼������Ԫ�س�Ϊ“Ͱ”��ntile������һ������������ָ��Ͱ������ ���SQL���ʹ��ntile������t_table��������װͰ������
�����SQL���IJ�ѯ�����ͼ9��ʾ��
����t_table���ļ�¼������6���������SQL����е�ntile����ָ����Ͱ��Ϊ4��
Ҳ���еĶ�������ôһ�����⣬SQL Server2005��ô������ijһͰӦ�÷Ŷ��ټ�¼�أ�����t_table���еļ�¼����Щ�٣���ô���Ǽ���t_table������59����¼����Ͱ����5����ôÿһͰӦ�Ŷ��ټ�¼�أ�
ʵ����ͨ������Լ���Ϳ��Բ���һ���㷨��������һ��ͰӦ�Ŷ��ټ�¼��������Լ�����£�
1. ���С��Ͱ�ŵļ�¼����С�ڱ�Ŵ��Ͱ��Ҳ����˵����1ͱ�еļ�¼��ֻ�ܴ��ڵ��ڵ�2Ͱ���Ժ�ĸ�Ͱ�еļ�¼��
2. ����Ͱ�еļ�¼Ҫô����ͬ��Ҫô��ijһ����¼���ٵ�Ͱ��ʼ��������ͱ�ļ�¼�������Ͱ�ļ�¼����ͬ��Ҳ����˵������и�Ͱ��ǰ��Ͱ�ļ�¼������10������4ͱ�ļ�¼����6����ô��5Ͱ�͵�6Ͱ�ļ�¼��Ҳ������6��
�������������Լ�������Եó����µ��㷨��
if(��¼���� mod Ͱ�� == 0)
{
recordCount = ��¼���� div Ͱ��;
��ÿͰ�ļ�¼������ΪrecordCount
}
else
{
recordCount1 = ��¼���� div Ͱ�� + 1;
int n = 1; // n��ʾͰ�м�¼��ΪrecordCount1�����Ͱ��
m = recordCount1 * n;
while(((��¼���� - m) mod (Ͱ�� - n)) != 0 )
{
n++;
m = recordCount1 * n;
}
recordCount2 = (��¼���� - m) div (Ͱ�� - n);
��ǰn��Ͱ�ļ�¼����ΪrecordCount1
��n + 1������������Ͱ�ļ�¼����ΪrecordCount2
}
����������㷨�������¼����Ϊ59��Ͱ��Ϊ5����ǰ4��Ͱ�ļ�¼������12�����һ��Ͱ�ļ�¼����11��
�����¼����Ϊ53��Ͱ��Ϊ5����ǰ3��Ͱ�ļ�¼��Ϊ11����2��Ͱ�ļ�¼��Ϊ10��
���ñ�����˵����¼����Ϊ6��Ͱ��Ϊ4��������recordCount1��ֵΪ2���ڽ���whileѭ�������recordCount2��ֵ��1����ˣ�ǰ2��Ͱ�ļ�¼��2����2��Ͱ�ļ�¼��1��
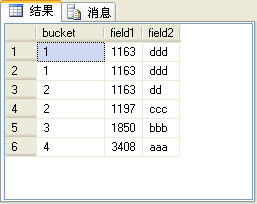
ͼ9
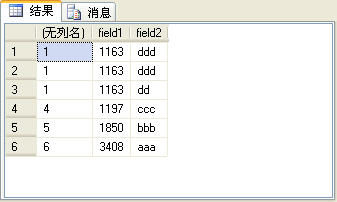
ͼ7
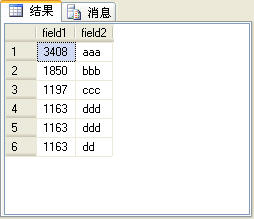
ͼ6
ͼ5
Access������QQ����Ⱥ (Ⱥ��:54525238) ������������AccessԴ������
�������:
 SQL SERVER2005 �ַ������� �����ı� 2011/11/4�� SQL SERVER2005���������ͬ�� �����ı� 2012/4/28�� SQL SERVER2005ʹ�ù��ñ�����ʽ��CTE����Ƕ��SQL �����ı� 2012/6/21�� SQL Server2005�����̳̣�ͼ�飩 ���廪��ѧ 2012/7/8�� SQL2005���ؼ���װͼ��\SQL Server2005�������Ŀ��������� ��sqlserver2005���� 2012/7/28�� SQL Server2005 �á���ҵ���Զ��������ݿ� ��Adolph Sun 2013/1/23��
SQL SERVER2005 �ַ������� �����ı� 2011/11/4�� SQL SERVER2005���������ͬ�� �����ı� 2012/4/28�� SQL SERVER2005ʹ�ù��ñ�����ʽ��CTE����Ƕ��SQL �����ı� 2012/6/21�� SQL Server2005�����̳̣�ͼ�飩 ���廪��ѧ 2012/7/8�� SQL2005���ؼ���װͼ��\SQL Server2005�������Ŀ��������� ��sqlserver2005���� 2012/7/28�� SQL Server2005 �á���ҵ���Զ��������ݿ� ��Adolph Sun 2013/1/23��Access����:
.gif)

�����ʴ�:
��������:
Դ��ʾ��
- ��Դ��QQȺ��19834647...(12.17)
- Access��ô��ÿ���������...(07.03)
- Access�Զ�����Ϣ��Msg...(04.28)
- Access��ô��ÿ���·�����...(03.09)
- Access��ô��������ͳ����...(02.26)
- Access��ô���������ͳ��...(01.26)
- ��Access��Ч�칫����һ��...(12.29)
- ��Access����������������...(11.03)
- ��Access��Ч�칫����һ��...(10.30)
- Access������RGBתCM...(09.22)

ѧϰ�ĵ�
- �豸װ���������ϵͳ������Acces...
- ����Ŀ������˾��������ϵͳ��Acces...
- ������Ŀ��ͬ����ϵͳ������Access...
- ��Access������������Ϣ����ϵͳ��
- �����żƻ���Ϣ����ƽ̨������Acces...
- ��TMSƽ̨���� �����㲿����Ӧ���г�...
- ���ز����Ž���ϵͳ��ʹ��ǿ����Acce...
- ���ֿ����ϵͳ��access���ݿ����...
- ����ҵ����ͬ����ϵͳ����Access...
- ��Access�ʹ���ƽ̨������Ⱦ���䷽...

��������
- Access��ô��ÿ������������...(07.03)
- Access���ݿⱸ�ݲ����ˡ�����...(06.29)
- ��θ��Ŀ��ٿ���ƽ̨�ϵĴ��尴ť(06.20)
- ��Excelģ��Access������...(06.17)
- Access���ٿ���ƽ̨������ͷ��...(06.15)
- Access2024�ٷ�����,Ac...(06.11)
- Access���ٿ���ƽ̨--��̨A...(06.03)
- ��bit�ֶε�Nullֵ����ΪFa...(06.01)
- ��VBA��������SQL SERVE...(05.30)
- ��SQL�������SQL Serve...(05.29)