
���ݿ�����
ʱ����:2016-08-12 08:12:32
������:��� ID��24010 ��������
ժ��Ҫ:һ������
�����ݿ������Ĺ�ע��δ�����ҵ��ǵ����ۣ���ô���ݿ�������ʲô���ģ��ۼ�������Ǿۼ�������ʲô��ͬ��ϣ�����ĶԸ�λͬ����һ���İ������в��ٴ��ɵĵط�������ϣ����λ���ߴͽ�ָ������ͬ������[�����ҳ֮���з����Ҳ��֪��������������ô�����ͣ����ͣ�����]
������:
����B-Tree
���dz��������ݿ�ϵͳ��������ʹ�õ����ݽṹ����B-Tree����B+Tree�����磬MsSqlʹ�õ���B+Tree��Oracle��Sysbaseʹ�õ���B-Tree���������ʼ���ؽ���һ��B-Tree��
B-Tree��ͬ��Binary Tree���������������������������һ��M��B-Tree��������������
1��ÿ�����������M�����ӣ�
2����������Ҷ����⣬����ÿ�����������M/2�����ӣ�
3��������������������ӣ����Ǹ���������һ����㣩��
4������Ҷ�����ͬһ�㣬Ҷ��㲻�����κιؼ�����Ϣ��
5����K���ؼ��ֵķ�Ҷ���ǡ�ð���K+1�����ӣ�
���⣬����һ����㣬���ڲ��Ĺؼ����Ǵ�С��������ġ�������B-Tree��M=4����������
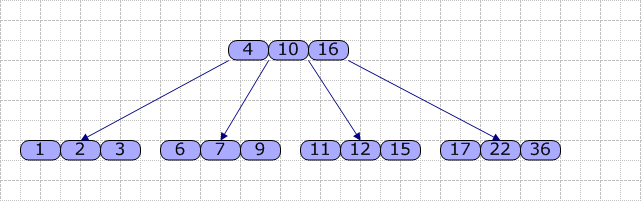
����ÿ����㣬��Ҫ����һ���ؼ�������Key[]��һ��ָ�����飨ָ����ӣ�Son[]����B-Tree�ڣ����ҵ������ǣ�ʹ��˳����ң����鳤�Ƚ϶�ʱ�����۰���ҷ�������Key[]���飬���ҵ��ؼ���K���ظý��ĵ�ַ��K��Key[]�е�λ�ã�����ȷ��K��ij��Key[i]��Key[i+1]֮�䣬���Son[i]��ָ���ӽ��������ң�ֱ����ij����в��ҳɹ�����ֱ���ҵ�Ҷ�����Ҷ����еIJ����Բ��ɹ�ʱ�����ҹ���ʧ�ܡ�
���ţ�����ʹ������ͼƬ��ʾ�������B-Tree��M=4�����β���1~6����
��ͼ�ɼ��������Dz���ؼ���4ʱ������ԭ����Ѿ����ˣ��ʽ��з��ѣ�������һ���ԭ����з��ѣ�Ȼ��ȡ���м�Ĺؼ���2�������������dz�Ϊ����㣩�������������ƣ���������һ����ŵĹ��̡�
�������ݿ�����
1��ʲô������
�����ݿ��У������ĺ������ճ������ϵġ�������һ�ʲ������������Сʱ����ֵ䣩����������������ݿ�����ݷ����ٶȵ����ݿ����
A���������Ա���ȫ��ɨ�衣������ѯ���Խ�ɨ����������ҳ������ҳ�������DZ�����������ҳ��
B�����ڷǾۼ���������Щ��ѯ�������Բ���������ҳ��
C���ۼ��������Ա������ݲ�����������ڱ������һ������ҳ��
D��һЩ����£������������ڱ������������
��Ȼ��������֪����Ȼ����������߲�ѯ�ٶȣ���������Ҳ�ᵼ�����ݿ�ϵͳ�������ݵ������½�����Ϊ�����ݸ�����Ҫͬʱ����������
2.�����Ĵ洢
һ��������¼�а����Ļ�����Ϣ��������ֵ�����㶨������ʱָ���������ֶε�ֵ��+��ָ�루ָ������ҳ������һ����ҳ����
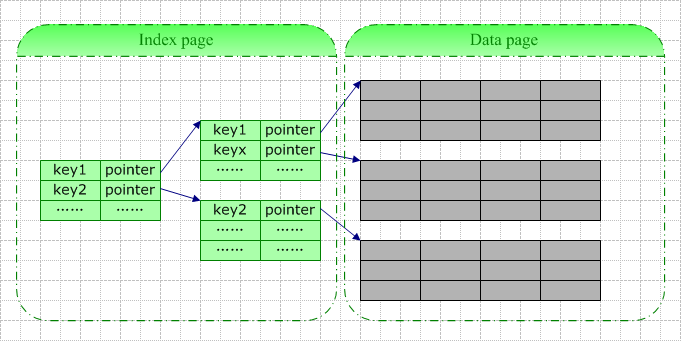
����Ϊһ�ſձ���������ʱ�����ݿ�ϵͳ��Ϊ�����һ������ҳ��������ҳ�����������ǰһֱ�ǿյġ���ҳ��ʱ���Ǹ���㣬Ҳ��Ҷ��㡣ÿ���������в���һ�����ݣ����ݿ�ϵͳ����˸�����в���һ��������¼�����������ʱ�����ݿ�ϵͳ��ְ����²�����з��ѣ�
A�������������ӽ��
B����ԭ������е����ݽ��Ƶز�����룬�ֱ�д���µ��������ӽ��
C��������м���ָ���������ӽ���ָ��
ͨ��״���£�����������¼�����������ֶ�ֵ���Լ�4-9�ֽڵ�ָ�룩������ʵ�����ʵ��������ҪС���࣬����ҳ�������ҳ��˵Ҫ�ܼ����ࡣһ������ҳ���Դ洢���������������¼������ζ���������в���ʱ��I/O��ռ�ܴ�����ƣ�������һ�������ڴӱ������˽�ʹ�����������ơ�
3������������
A���ۼ������������ݰ���������˳�����洢�ġ����ھۼ�������Ҷ�ӽ�㼴�洢����ʵ�������У����������ⵥ��������ҳ��
B���Ǿۼ������������ݴ洢˳��������˳���ء����ڷǾۼ�������Ҷ�����������ֶ�ֵ��ָ������ҳ�����е���ָ�룬�ò��������ҳ���������������ݱ���������һ�¡�
��һ�ű���ֻ�ܴ���һ���ۼ���������Ϊ��ʵ���ݵ�����˳��ֻ������һ�֡����һ�ű�û�оۼ���������ô������Ϊ���Ѽ�����Heap���������ı��е�������û���ض���˳�����е����н������ӵı���ĩβλ�á�
4���ۼ�����
�ھۼ������У�Ҷ���Ҳ�����ݽ�㣬���������еĴ洢˳���������Ĵ洢˳��һ�¡�
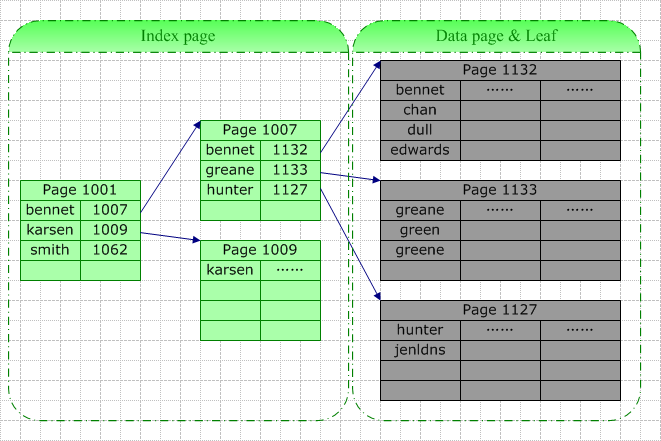
1���ۼ��������ѯ����
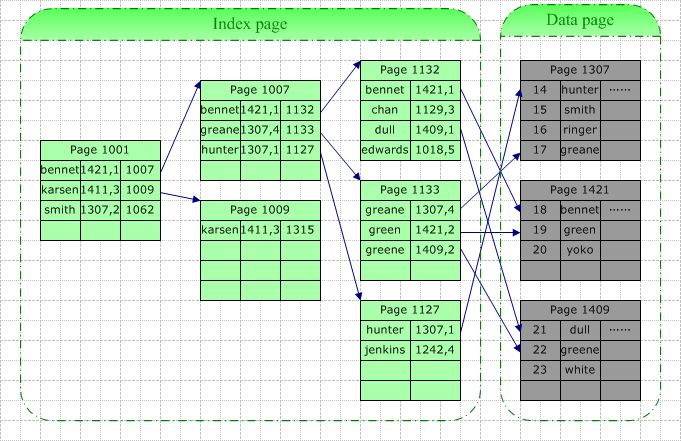
����ͼ�������������ֶ��Ͻ����ۼ�����������Ҫ�ڸ��ݴ��ֶβ����ض��ļ�¼ʱ�����ݿ�ϵͳ������ض���ϵͳ�����ҵĴ������ĸ���Ȼ�����ָ�������һ����ֱ���ҵ�����������Ҫ��ѯ��Green��������������[Bennet,Karsen]���ݴ������ҵ�������ҳ1007���ڸ�ҳ�С�Green������[Greane, Hunter]�䣬�ݴ������ҵ�Ҷ���1133��Ҳ�����ݽ�㣩���������ڴ�ҳ��������Ŀ�������С�
�˴β�ѯ��IO����3������ҳ�IJ�ѯ���������һ��ʵ������������ҳ�в�ѯ��������IJ��ҿ����ǴӴ��̶�ȡ(Physical Read)���Ǵӻ����ж�ȡ(Logical Read)������˱�����Ƶ�ʽϸߣ���ô�������нϸ߲�������ܿ����ڻ����б��ҵ�������������IO����С������������
2���ۼ�������������
�������£�����������������ҵ���Ӧ������ҳ��Ȼ��ͨ��Ų�����еļ�¼Ϊ�������ڳ��ռ䣬���������ݡ�
�������ҳ����������Ҫ�������ҳ��ҳ�����һ�ֺķ���Դ�IJ�����һ�����ݿ�ϵͳ�л�����Ӧ�Ļ���Ҫ��������ҳ��ֵĴ�����ͨ����ͨ��ΪÿҳԤ���ռ���ʵ�֣���
A���ڸ�ʹ�õ����ݶΣ�extent���Ϸ����µ�����ҳ��������ݶ�����������Ҫ�����¶Ρ�
B����������ָ�룬����Ҫ����Ӧ������ҳ�����ڴ沢������
C����Լ��һ��������б������µ�����ҳ�С�
D����������зǾۼ�����������Ҫ������Щ����ָ���µ�����ҳ��
���������
A������²����һ����¼�����ܴ�����ݣ����ܻ��������������ҳ������֮һ�����洢�¼�¼����һ�洢��ԭҳ�в�ֳ��������ݡ�
B��ͨ�����ݿ�ϵͳ�лὫ�ظ������ݼ�¼�洢����ͬ��ҳ�С�
C��������������Ϊ�ۼ������ģ����ݿ�ϵͳ���ܲ����������ҳ��ҳֻ�Ǽ���������ҳ��
3���ۼ�������ɾ������
ɾ���н��������·��������������ƶ������ɾ����¼��ɵĿհס�
���ɾ�������Ǹ�����ҳ�е����һ�У���ô������ҳ�������գ���Ӧ������ҳ�еļ�¼����ɾ����������յ�����ҳλ�ڸ��ñ�����������ҳ��ͬ�Ķ��ϣ���ô������������ʱ���ڱ����á����������ҳ�Ǹöε�Ψһһ������ҳ����ö�Ҳ�����ա�
�������ݵ�ɾ�����������ܵ�������ҳ�н���һ����¼����ʱ���ü�¼���ܻᱻ�����ڽ�������ҳ�У�ԭ����ҳ�������գ�����ν�ġ������ϲ�����
5���Ǿۼ�����
�Ǿۼ�������ۼ�������ȣ�
A��Ҷ�ӽ�㲢�����ݽ��
B��Ҷ�ӽ��Ϊÿһ�����������д洢һ������-ָ�롱��
C��Ҷ�ӽ���л��洢��һ��ָ��ƫ����������ҳָ�뼰ָ��ƫ�������Զ�λ������������С�
D�����Ƶģ��ڳ�Ҷ����������������㣬�洢��Ҳ�����Ƶ����ݣ�ֻ��������ָ����һ��������ҳ�ġ�
�ۼ�������һ��ϡ������������ҳ��һ��������ҳ�洢����ҳָ�룬��������ָ�롣�����ڷǾۼ������������ܼ�������������ҳ����һ������ҳ��Ϊÿһ�������д洢һ��������¼��
���ڸ����м伶��������¼�����Ľṹ������
A�������ֶ�ֵ
B��RowId������Ӧ����ҳ��ҳָ��+ָ��ƫ���������ڸ߲������ҳ�а���RowId��Ϊ�˵����������ظ�ֵʱ������������ʱ��ȷ��λ�����С�
C����һ������ҳ��ָ��
����Ҷ�Ӳ�������������Ľṹ������
A�������ֶ�ֵ
B��RowId
1���Ǿۼ��������ѯ����
�����ͼ���������ͬ�����ҡ�Green������ôһ�β�ѯ��������������IO��3������ҳ�Ķ�ȡ+1������ҳ�Ķ�ȡ��ͬ�������ڻ���Ĺ�ϵ����ʵ��IOʵ�ʿ���ҪС�������г��ġ�
2���Ǿۼ�������������
���һ�ű�����һ���Ǿۼ�������û�оۼ����������µ����ݽ������뵽��ĩһ������ҳ�У�Ȼ��Ǿۼ������������¡����Ҳ�����ۼ��������þۼ������������ڲ������н�Ҫ����ʲôλ�ã���ۼ��������Լ��Ǿۼ������������¡�
3���Ǿۼ�������ɾ������
�����ɾ�������Where�Ӿ��а��������ϣ����зǾۼ���������ô�÷Ǿۼ������������ڲ��������е�λ�ã�����ɾ��֮��λ������Ҷ���ϵĶ�Ӧ��¼Ҳ����ɾ��������ñ����������Ǿۼ�������������Ҷ�ӽ���ϵ���Ӧ����ҲҪɾ����
���ɾ���������Ǹ�����ҳ�е�Ψһһ�������ҳҲ�����գ�ͬʱ��Ҫ���¸����������ϵ�ָ�롣
����û���Զ��ĺϲ����ܣ����Ӧ�ó�������Ƶ�������ɾ�������������ܵ��±������������ҳ����ÿ��ҳ��ֻ���������ݡ�
6����������
��������������һ���������ԣ���ijһ��ѯ�а����������ֶν�����һ�������У���ʱ�����������߲�ѯ���ܡ�
��������ֶε���������Ϊ����������������������31���ֶΣ�������¼���Ϊ600B������������ɸ��ֶ��ϴ�����һ�����ϵķǾۼ�����������IJ�ѯ������Select�ֶμ�Where,Order By,Group By,Having�Ӿ������漰���ֶζ������������У���ֻ��������ҳ���������ѯ��������Ҫ��������ҳ�����ڷǾۼ�������Ҷ�����������������е�������ֵ��ʹ����Щ��㼴�ɷ������������ݣ����������֮Ϊ���������ǡ���
���������ǵ�����£�������������ɨ�裺
A��ƥ������ɨ��
B����ƥ������ɨ��
1��ƥ������ɨ��
��������ɨ�����������ʡȥ��������ҳ�IJ��裬����ѯ������һ������ʱ��������������ģ����ڷ�Χ��ѯ������£�������߽�������������������������
��Դ���ɨ�裬�������������ѯ���漰�ĵ������ֶΣ����⣬����Ҫ���㣺Where�Ӿ��а��������еġ������С���Leading Column��������һ��������������A,B,C,D���У���AΪ�������С������Where�Ӿ�������������BCD����BD���������ֻ��ʹ�÷�ƥ������ɨ�衣
2������������ɨ��
�������������Where�Ӿ��в����������ĵ����У���ô��ʹ�÷���������ɨ�衣�����յ���ɨ���������ϵ�����Ҷ�ӽ�㣬��Ȼ����������ͨ����ǿ��ɨ�����е�����ҳ��
[�ο�]
[1]http://manuals.sybase.com/onlinebooks/group-asarc/asg1200e/aseperf/@Generic__BookTextView/3358
[2] http://publib.boulder.ibm.com/infocenter/idshelp/v10/index.jsp?topic=/com.ibm.adref.doc/adref235.htm
Access������QQ����Ⱥ (Ⱥ��:54525238) ������������AccessԴ������
�������:
 SQLServer���ݿ������Ļ���֪ʶ ������ת�� 2015/1/27�� Ψһ�����ͷ�Ψһ������������� ����ѫ 2015/4/9�� Access����ʱ�������ڽ������������ؼ��֡����ϵ�д����ظ���ֵ������Ա��ĸı�û�гɹ����ı���ֶ��л�����ظ����ݵ��ֶ��е����ݣ�ɾ�����������¶��������������ظ���ֵ������һ�Ρ��Ľ������3 ���ų� 2015/10/1�� Access����ʱ�������ڽ������������ؼ��֡����ϵ�д����ظ���ֵ������Ľ������ ���ų� 2015/11/1�� Access����ƽ̨--��������ʱ������'-2147217887'�����ڽ������������ؼ��֡����ϵ�д����ظ���ֵ������Ա��ĸı�û�гɹ����ı���ֶ��л�����ظ����ݵ��ֶ��е����ݣ�ɾ�����������¶��������������ظ���ֵ������һ�Ρ��Ľ������ ���ų� 2016/8/7��
SQLServer���ݿ������Ļ���֪ʶ ������ת�� 2015/1/27�� Ψһ�����ͷ�Ψһ������������� ����ѫ 2015/4/9�� Access����ʱ�������ڽ������������ؼ��֡����ϵ�д����ظ���ֵ������Ա��ĸı�û�гɹ����ı���ֶ��л�����ظ����ݵ��ֶ��е����ݣ�ɾ�����������¶��������������ظ���ֵ������һ�Ρ��Ľ������3 ���ų� 2015/10/1�� Access����ʱ�������ڽ������������ؼ��֡����ϵ�д����ظ���ֵ������Ľ������ ���ų� 2015/11/1�� Access����ƽ̨--��������ʱ������'-2147217887'�����ڽ������������ؼ��֡����ϵ�д����ظ���ֵ������Ա��ĸı�û�гɹ����ı���ֶ��л�����ظ����ݵ��ֶ��е����ݣ�ɾ�����������¶��������������ظ���ֵ������һ�Ρ��Ľ������ ���ų� 2016/8/7��Access����:
.gif)

�����ʴ�:
��������:
Դ��ʾ��
- ��Դ��QQȺ��19834647...(12.17)
- Access�Զ�����Ϣ��Msg...(04.28)
- Access��ô��ÿ���·�����...(03.09)
- Access��ô��������ͳ����...(02.26)
- Access��ô���������ͳ��...(01.26)
- ��Access��Ч�칫����һ��...(12.29)
- ��Access����������������...(11.03)
- ��Access��Ч�칫����һ��...(10.30)
- Access������RGBתCM...(09.22)
- Access������RGB��ɫ��...(09.15)

ѧϰ�ĵ�
- �豸װ���������ϵͳ������Acces...
- ����Ŀ������˾��������ϵͳ��Acces...
- ������Ŀ��ͬ����ϵͳ������Access...
- ��Access������������Ϣ����ϵͳ��
- �����żƻ���Ϣ����ƽ̨������Acces...
- ��TMSƽ̨���� �����㲿����Ӧ���г�...
- ���ز����Ž���ϵͳ��ʹ��ǿ����Acce...
- ���ֿ����ϵͳ��access���ݿ����...
- ����ҵ����ͬ����ϵͳ����Access...
- ��Access�ʹ���ƽ̨������Ⱦ���䷽...

��������
- Access���ٿ���ƽ̨������ͷ��...(06.15)
- Access2024�ٷ�����,Ac...(06.11)
- Access���ٿ���ƽ̨--��̨A...(06.03)
- ��bit�ֶε�Nullֵ����ΪFa...(06.01)
- ��VBA��������SQL SERVE...(05.30)
- ��SQL�������SQL Serve...(05.29)
- Access���ٿ���ƽ̨--ͼƬ��...(05.29)
- �����VBA������û����������(05.28)
- ��VBA��ָ��ͼ���к�����/������...(05.25)
- ����ƾ�о�������Access����˼...(05.25)